Swapnil Gourshete
Swapnil Gourshete When it comes to performance of an application, databases are highly important and effective. And one of the key factor in database optimisation is index. It helps in getting results faster for select and where queries.

What is Index ?
Index is simply a data-structure that holds pointer to rows that has value for a column. It narrows down the number of rows to look out for. Indexes can be created using one of the B-tree, Hash, GiST, GIN.
- Comparison of B-tree/Hash/Gist (Generalised Search Tree) /GIN (Generalised Inverted Index)
Skip this if you know B-tree and Hash comparison. Most commonly index are created using B-tree, because they are very efficient in time complexity. As well B-tree can handle equality and range queries i.e.<, ≤, >, ≥ operations. B-tree can also sort data in it. Hash indexes can only handle equality(=) operations. Use of Hash index is discouraged by postgresql due to some issues.
Hash index operations are not presently WAL-logged, so hash indexes might need to be rebuilt with REINDEX after a database crash if there were unwritten changes. Also, changes to hash indexes are not replicated over streaming or file-based replication after the initial base backup, so they give wrong answers to queries that subsequently use them. For these reasons, hash index use is presently discouraged.
-
Syntax for Creating index
CREATE INDEX index_name ON table_name (column1, column2, ..);
How Index works ?
Suppose we have a users table(id, name) indexed on name. When a record is inserted in users table, respective entry in B-tree would be made. At the moment users table have entries (1, ‘Deepak’), (2, ‘Rohit’), (3, ‘MSD’), (4, ‘Aaradhya’). The indexed B-tree would look like [Aaradhya, Deepak, MSD, Rohit].
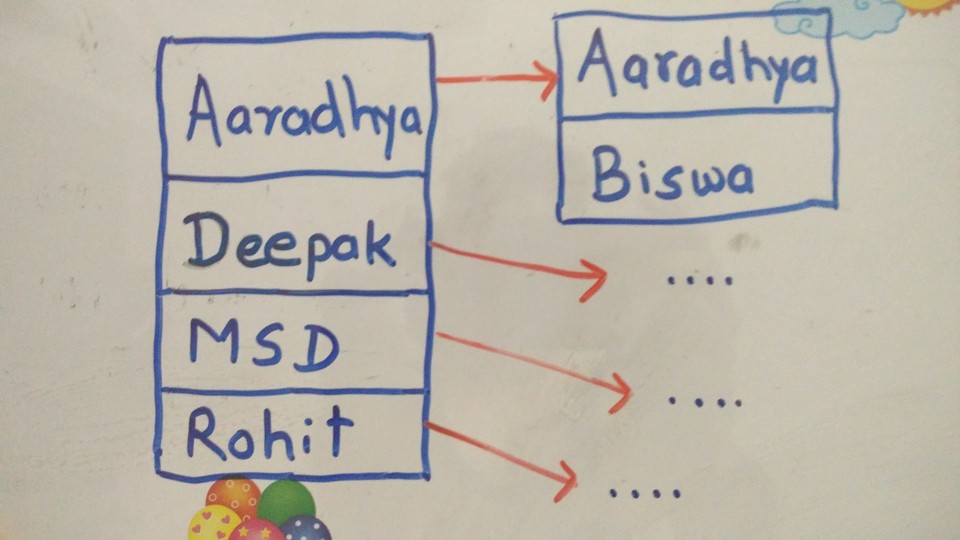
For instance, I insert a record (5, ‘Swapnil’), B-tree would be updated to [Aaradhya, Deepak, MSD, Rohit] and node Rohit will point to [Rohit, Swapnil]. The searching operation are made easy because the data is sorted. If you are interested in postgresql code, take a look here on how postgresql works. When search query for name Swapnil is fired, unlike sequentially traversing users table as in without indexing, B-tree will efficiently find it is in node Rohit. Note that after locating node, it switches to binary search to reach Swapnil. Here is the source code to search value in single B-tree in postgresql.
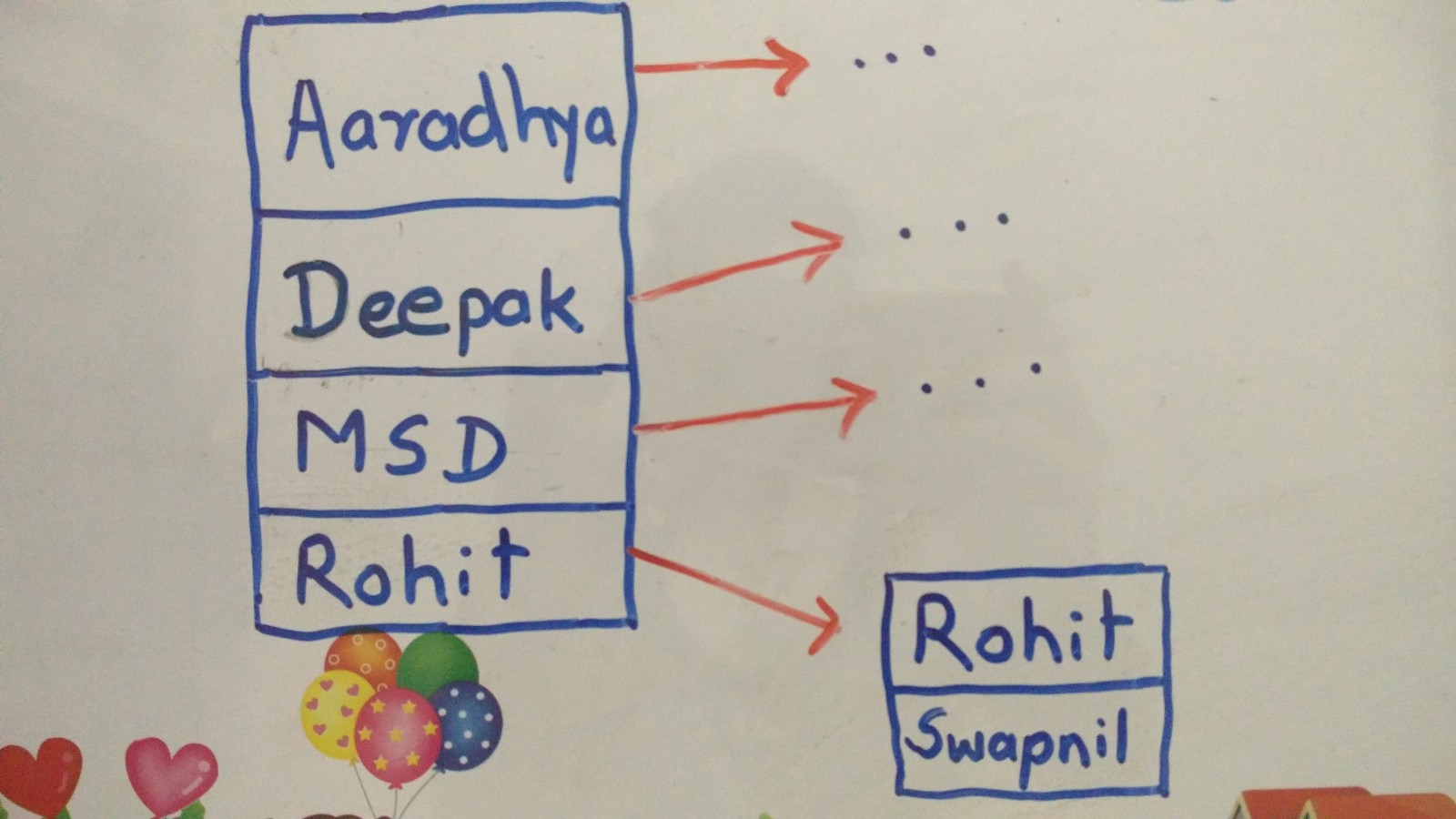
A take on insert/update with index
Insert is the only operation which do not directly benefits from index, as it do not include where clause. Additionally it increases time for inserting. Let’s take a look. When not using index, a database insert operation would only add a row to table. But while using index, it additionally needs to add index-entry in B-tree. And it takes time, first to lookup appropriate node, assign value to node then to maintain B-tree split the node, if needed.
In update query, when record is updated in database, the index for the same also gets updated.
Building indexes concurrently
Most database systems allow to perform reads while creating index in a single scan, but lock parallel write operations. Transactions involving insert, update, delete will be blocked until index build is finished. And this could have sever impact if system is a live production database.
Postgresql supports building indexes without locking with CONCURRENTLY option of CREATE INDEX. It performs two scans of table. First index is entered in system catalog in one transaction. Then two transactions perform two scans. Before each table scan, the index build must wait for existing transactions that have modified the table to terminate. After the second scan, the index build must wait for any transactions that have a snapshot predating the second scan to terminate. When these write operations are done, both scans complete and assures updated data. The reads were never a problem. Read more
CREATE INDEX CONCURRENTLY index_name ON table_name (column1, column2, ..);
Unique Indexes
A unique index guarantees that the table doesn’t have more than one row with the same value. It’s advantageous to create unique indexes for two reasons: data integrity and performance. Lookups on a unique index are very fast.
Note -
In terms of data integrity, using a validates_uniqueness_of validation on an ActiveModel class doesn’t really guarantee uniqueness because there can and are concurrent users creating invalid records. Therefore, always create the constraint at the database level - either with an index or a unique constraint.
Last Stop
- Indexes does not store values of columns other than indexed ones.
- Indexes should be created on columns which are queried frequently.
- To optimise insert performance, it is very important to keep the number of indexes small.
Have a great day! Cheers!!!
 APIs in Rails 5.0 - overview
APIs in Rails 5.0 - overview