 Swapnil Gourshete
Swapnil Gourshete 
As name suggests it is way of dividing database table into smaller parts generally called as partitions. Partitioning logic can vary from use case to use case. For example, we might partition users table based on ID i.e. IDs from 1 to 1,000,000 will be in first partition, IDs from 1,000,001 to 2,000,000 would be second one and like this. Another example would be based on created date, for example - All entries from 2020 would go in one partition, entries from 2021 would go in another one and so on.
When?
It is fair to ask when to partition table in first place. The straight forward answer would be when table data grows to a fairly large size and querying on it becomes slow and painful for database, we should look into aspect of partitioning the table.
Benefits of partitioning -
As we are dividing table into smaller chunks, searching of data becomes relatively faster. Also in Postgres, database is smart enough to only look into particular partitions based on logic in where clause. Also maintenance operations like vacuuming are performed on relatively small and updated datasets.
A bit about our use case -
We have product_views table which stores information about views received on products across the platform. Over the time and by the nature of data, this table grew to a size of 20 GB, having over 50 million rows. The querying of data from this table was now relatively slow (even though we have proper indices maintained for this table) and it was sheerly because of volume of data. So what do we do now? Looking into data and size we decided to partition this table.
Here is how we achieved it. Our tech stack is backend powered by Ruby on rails and Postgres database. We wanted to do it with minimal changes on rails part and more on Postgres part. Postgres supports partitioning from version 11 onwards. We divided the table by created_at column yearwise. A postgresql script to create partition is -
CREATE TABLE orders (
id SERIAL,
order_date DATE NOT NULL,
customer_id INTEGER,
amount DECIMAL(10, 2)
) PARTITION BY RANGE (order_date);
CREATE TABLE orders_2019 PARTITION OF orders
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01');
CREATE TABLE orders_2020 PARTITION OF orders
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');
CREATE TABLE orders_2021 PARTITION OF orders
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
CREATE TABLE orders_2022 PARTITION OF orders
FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');
CREATE TABLE orders_2023 PARTITION OF orders
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
CREATE TABLE orders_2024 PARTITION OF orders
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
This will create the db schema discussed above. Now let’s put some data to play around. I have used this script to put random 1 million rows into database.
require 'benchmark'
require 'pg'
class OrderGenerator
BATCH_SIZE = 10_000
TOTAL_RECORDS = 1_000_000
START_DATE = Date.new(2019, 1, 1)
END_DATE = Date.new(2024, 12, 31)
TOTAL_DAYS = (END_DATE - START_DATE).to_i + 1
def self.generate_orders
conn = PG.connect(dbname: 'your_database_name')
time = Benchmark.measure do
(0...TOTAL_RECORDS).each_slice(BATCH_SIZE) do |batch|
values = batch.map do
order_date = random_date
customer_id = rand(1..100_000)
amount = rand(10.0..1000.0).round(2)
"(DATE '#{order_date}', #{customer_id}, #{amount})"
end.join(',')
sql = "INSERT INTO orders (order_date, customer_id, amount) VALUES #{values}"
conn.exec(sql)
print '.' # Progress indicator
end
end
puts "\nTime taken: #{time.real.round(2)} seconds"
puts "Total records inserted: #{conn.exec("SELECT COUNT(*) FROM orders").getvalue(0,0)}"
ensure
conn.close if conn
end
def self.random_date
START_DATE + rand(TOTAL_DAYS)
end
end
# Generate orders
OrderGenerator.generate_orders
BOOM! It ran in 4.2 Seconds.
Running queries
Now we have all the setup needed, let’s jump to the exciting part.
Finding entries from same year
This would be the query to finding records from the year 2020 from the partitioned table.
select * from orders where order_date between '2020-07-11' and '2020-08-11'
But how will we assured that it is using partitioned table? Simple, analyze the query.
explain analyze
select * from orders where order_date between '2020-07-11' and '2020-08-11'
And the output is -
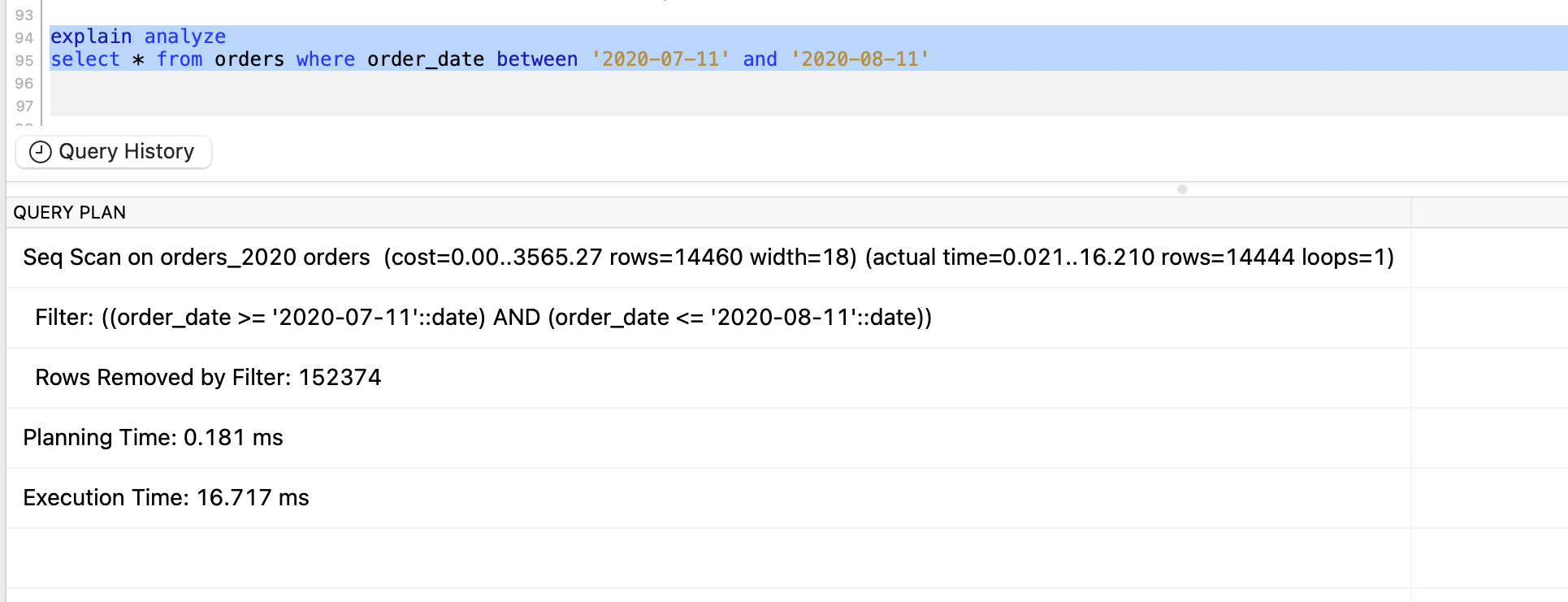
You can see that the data is being pulled from orders_2020 table which confirms partition is working. I am just wondering if the execution time can be reduced. What can we do? Let’s try putting an index on these tables.
Note - For PostgreSQL 11 and later:
We can create a global index on the partitioned table, which will automatically propagate to all partitions:
CREATE INDEX idx_orders_order_date ON orders (order_date);
This single command will create the index on the parent table and all existing and future partitions.
Let’s rerun our query and see the result -
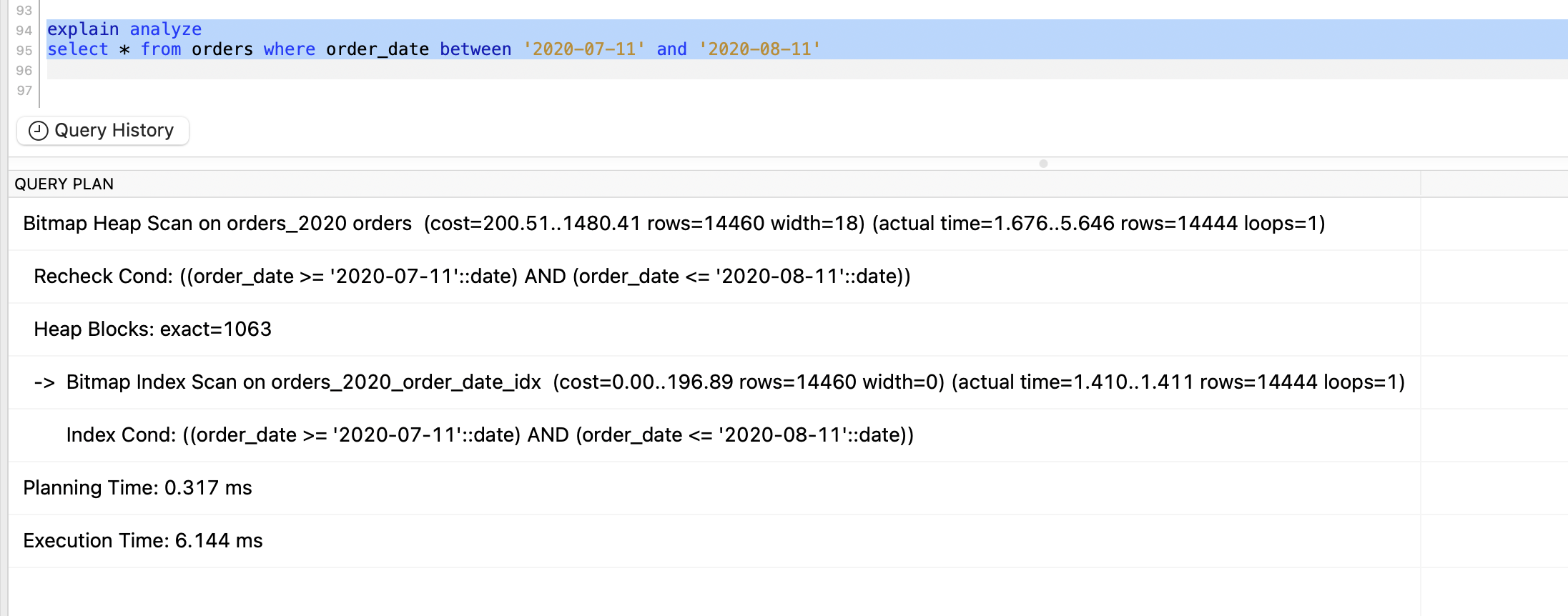
Wow the time is reduced by 61%. This is just awesome.
Finding entries from different years
Let’s find out records from different years.
Query -
explain analyze
select * from orders where order_date between '2020-12-11' and '2021-01-11'
And it is executed around 10ms, which is good. Also we can see the Bitmap Heap Scan used by query planner.
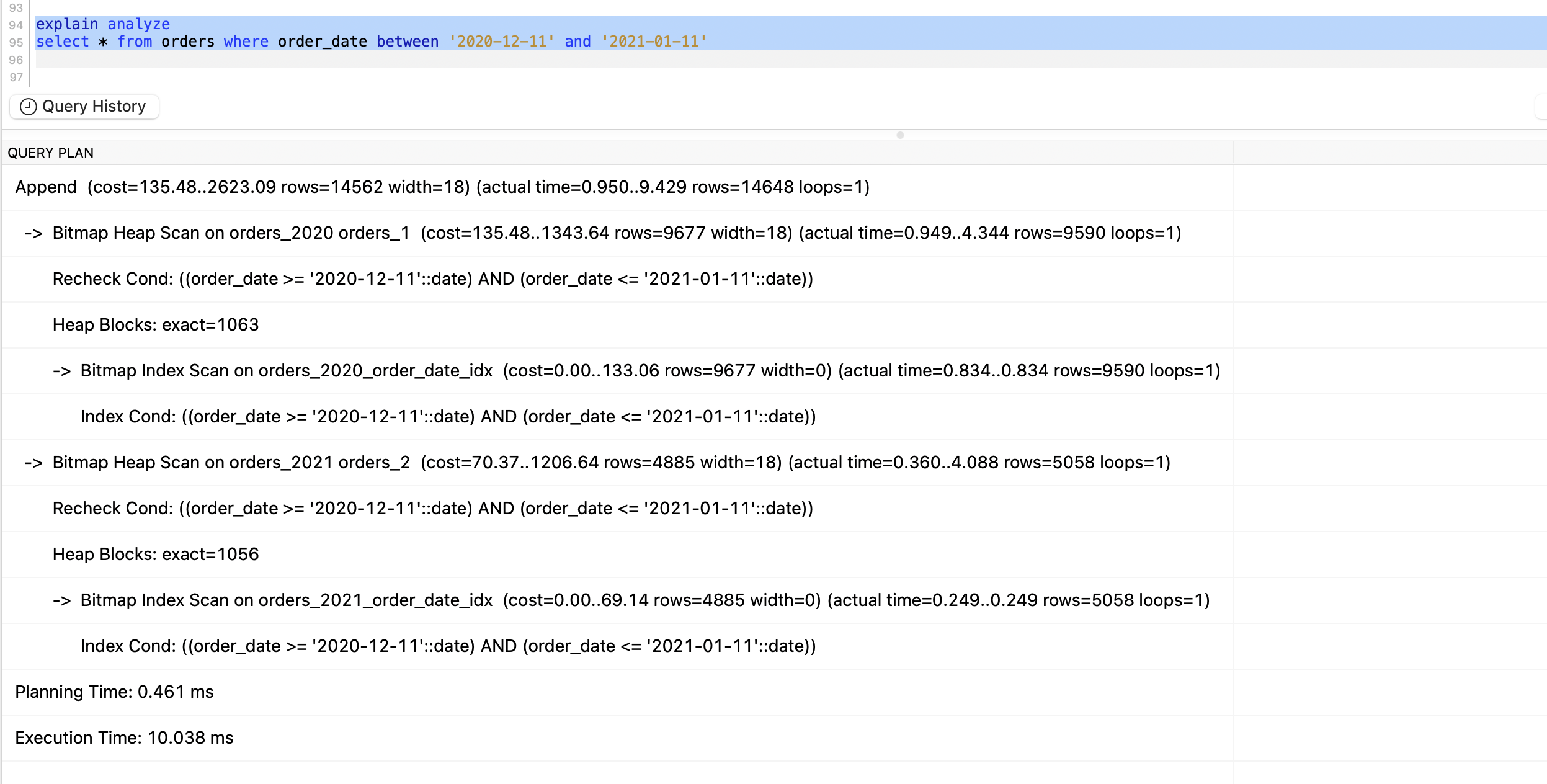
Did index made any difference here?
To find out answer to this question, let’s drop the index & run query again -
DROP INDEX idx_orders_order_date
explain analyze
select * from orders where order_date between '2020-12-11' and '2021-01-11'
And no surprise here. The execution time is increased by 4x.
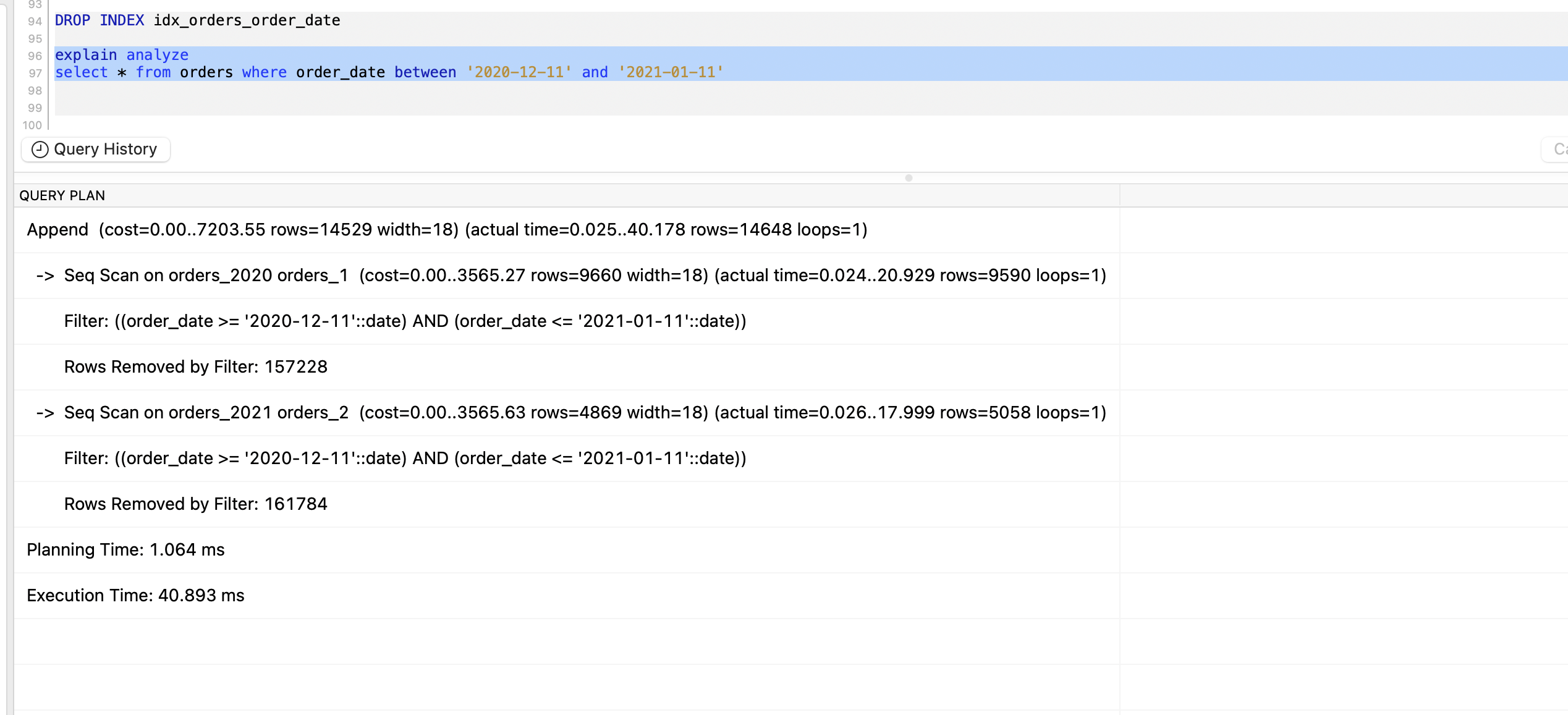
That’s it from this post. I hope this was interesting!
 HTTP Status Codes: An Overview
HTTP Status Codes: An Overview